Introduzione
Contents
Introduzione#
CKAN si definisce un Data Management System (DMS), un’applicazione specializzata che ricade nella più vasta categoria di Content Management System (CMS) resa popolare da Wordpress.
DMS (Data Management System) e DBMS (Database Management System) sono due concetti profondamente diversi, da non confondere.
In CKAN in contenuti di prima classe sono i dataset, quindi insiemi ordinati e omogenei di dati (nella maggior parte dei casi in forma tabellare).
Un dato (dal latino datum che significa dono, cosa data) è una descrizione elementare codificata di un’informazione, un’entità, di un fenomeno, di una transazione, di un avvenimento (da Wikipedia).
In generale tutto ciò che viene misurato, contestualizzato e codificato (tramite strumenti o attraverso i sensi) è un dato. Si tratta di una rappresentazione della realtà che dipende da una serie di scelte (più o meno consapevoli, più o meno giustificate) e che quindi è caratterizzata da un certo grado di soggettività.
In particolare la natura soggettiva del dato si esprime su due livelli:
durante la produzione del dato nelle fasi di misura e codifica
durante la fruizione del dato nella fase di interpretazione
Un insieme ordinato e omogeneo di dati (es. la stessa misura a tempi diversi o in luoghi diversi) si chiama dataset e la sua rappresentazione più nota e usata è quella tabellare, in accordo con i principi del modello relazionale.
Tutte le informazioni relative al contesto di produzione o fruizione di un insieme di dati non trovano generalmente spazio in un dataset, né possono mai essere considerati così evidenti da poter essere omessi del tutto. Si tratta di informazioni che descrivono i dati e per questo vengono chiamate metadati.
CKAN è uno strumento per gestire metadati (ed eventualmente dati).
Dati e metadati#
Un dataset rappresenta qualitativamente e quantitativamente un fenomeno. Lo si costruisce scegliendo cosa osservare (scelta delle osservabili), misurando le osservabili scelte (processo di misura), raccogliando i dati così prodotti in un insieme strutturato (costruzione del dataset).
Nel modello relazionale, una tabella rappresenta un dataset, ogni colonna una osservabile, ogni riga una misura. Nelle celle trovano posto i dati, cioè i risultati di tutte le misure di tutte le osservabili.
Stanza |
Temperatura |
Umidità |
Volume |
Dimensione |
Descrizione |
|---|---|---|---|---|---|
Camera da letto |
22.6 |
48 |
40 |
Grande |
Una normale camera matrimoniale con un armadio, un letto e due comodini. |
Cucina |
24.8 |
76 |
34 |
Media |
Una cucina spaziosa completamente arredata. |
Bagno |
23.1 |
89 |
28 |
Piccola |
Un bagno piccolo, ma confortevole, con doccia. |
Le osservabili possono essere di quattro tipi:
categoriali nominali (es. Stanza)
categoriali ordinali (es. Dimensione)
cardinali (es. Temperatura, Umidità, Volume)
testuali (es. Descrizione)
Le osservabili categoriali possono rappresentare anche dati relazionali, se contengono delle chiavi esterne che identificano univocamente righe di altre tabelle.
Le tabelle possono rappresentare anche dati che non rispettano i principi del modello relazionale, per esempio essere tabelle a doppia entrata o tabelle pivot che mostrano dati aggregati.
Nella tabella di esempio ci sono tutti i dati, ma mancano ancora delle informazioni fondamentali. Per esempio, le unità di misura delle tre osservabili cardinali. Si tratta dei metadati, che contengono informazioni utili a interpretare correttamente i dati.
I metadati possono essere inseriti all’interno dell’intestazione delle colonne (es. Temperatura (°C, Umidità (%), Volume (mq)), ma in questo caso non sono strutturati, quindi non possono essere efficacemente elaborati da una macchina.
Strutturare un insieme di metadati significa costruirne un dataset e rappresentarlo sotto forma di tabella. Questa tabella di metadati descrive lo schema della tabella di dati iniziale.
Nome osservabile |
Tipologia osservabile |
Tipo di dato |
Valori ammessi |
Unità di misura |
|---|---|---|---|---|
Stanza |
Categoriale nominale |
String |
Camera da letto, Cucina, Bagno, Salone, Ripostiglio |
|
Temperatura |
Cardinale |
Float |
-273.15 – +Inf |
°C |
Umidità |
Cardinale |
Integer |
0 – 100 |
% |
Volume |
Cardinale |
Float |
0 – +Inf |
mq |
Dimensione |
Categoriale ordinale |
String |
Grande, Media, Piccola |
|
Descrizione |
Testo libero |
String |
Mancano però ancora delle informazioni relative al contesto in cui le misure sono state effettuate. Per esempio autore / autrice delle misure, data e orario della raccolta dati, proprietario della casa in questione, modalità di riutilizzo dei dati, ecc.
Per strutturare anche queste informazioni è normalmente sufficiente una lista di coppie chiave / valore, rappresentabile con una tabella a due colonne.
Metadato |
Valore |
|---|---|
Author |
Alessio |
Creation date |
07/10/2022 |
Update date |
11/10/2022 |
Owner |
Marco |
License |
CC-BY |
CKAN è stato sviluppato principalmente per gestire tabelle di metadati come queste e renderle machine-readable. CKAN permette di creare, aggiornare, pubblicare e rendere ricercabili cataloghi di dataset, descritti dai loro metadati. In questo senso è più correttamente un Metadata Management System.
I dati veri e propri, invece, sono gestiti come risorse associate a un dataset e possono essere di vario tipo: semplici link esterni, file CSV, archivi ZIP, ecc. Lo stesso dataset può essere caricato e reso scaricabile in più formati diversi, per esempio CSV e JSON.
Standard e formati#
In order to be useful, metadata needs to be standardized. This includes agreeing on language, spelling, date format, etc. A key component of metadata is the schema. If no standard is used, it can be very difficult to compare data sets.
L’interoperabilità tra contesti e sistemi diversi è possibile solo se esistono standard condivisi che compongono un linguaggio comune. L’acronimo F.A.I.R. riassume i quattro principi cardine che caratterizzano un ecosistema virtuoso di dati e metadati (per approfondire vedi GO Fair Initiative).
Findability
Accessibility
Interoperability
Reusability
Esistono numerosi schemi dati standard, solitamente applicabili in specifici contesti semantici. L’esempio più famoso è Schema.org, specializzato in schemi per descrivere pagine web.
Fissato uno standard, schemi e dati possono essere salvati e pubblicati in diversi formati, per esempio RDFa, Microdata, JSON-LD nel caso di Schema.org.
Anche la gestione dei metadati ha bisogno di standard condivisi e ne esistono diversi, di applicazione più generale o più legata a un contesto specifico. L’esempio più famoso è Dublin Core che offre uno schema per descrivere generiche risorse.
Nello specifico ambito dei cataloghi dati, il W3C raccomanda lo standard DCAT (Data Catalog Vocabulary).
Sharing data resources among different organizations, researchers, governments and citizens requires the provision of metadata. DCAT is a vocabulary for publishing data catalogs on the Web, which was originally developed in the context of government data catalogs such as data.gov and data.gov.uk, but it is also applicable and has been used in other contexts.
L’Unione Europea ha fatto proprie le specifiche del W3C con qualche modifica e raccomanda l’uso di DCAT-AP (DCAT Application Profile for data portals in Europe) per i cataloghi dati nazionali e continentali.
In passato l’Italia si è uniformata alle specifiche europee rilasciando un proprio profilo nazionale compatibile con quello europeo e internazionale, ma l’attuale versione del DCAT-AP_IT è ancora legata alla versione 1 di DCAT e DCAT-AP, ormai alla versione 2.
CKAN utilizza un suo schema dati proprietario per rappresentare i metadati di catalogo, dataset e risorse che gestisce, descritto dalle specifiche delle sue API. Esiste però un’estensione ufficiale che aggiunge la compatibilità con DCAT e DCAT-AP: CKANext-DCAT. L’estensione italiana per il supporto a DCAT-AP_IT è al momento mantenuta dalla società GeoSolutions S.A.S.: CKANext-DCATAPIT.
Open data e open source#
Legalmente un dataset è considerato un’opera creativa dell’ingegno come un romanzo o il codice sorgente di un’applicazione e in quanto tale è soggetta al diritto d’autore.
Se la banca dati è una creazione intellettuale originale, è possibile proteggerla mediante il diritto d’autore, che conferisce il diritto esclusivo di riprodurre, adattare, distribuire la banca dati o variazioni della stessa. Il diritto d’autore tutela la struttura della banca dati e non i suoi contenuti (da europa.eu/youreurope).
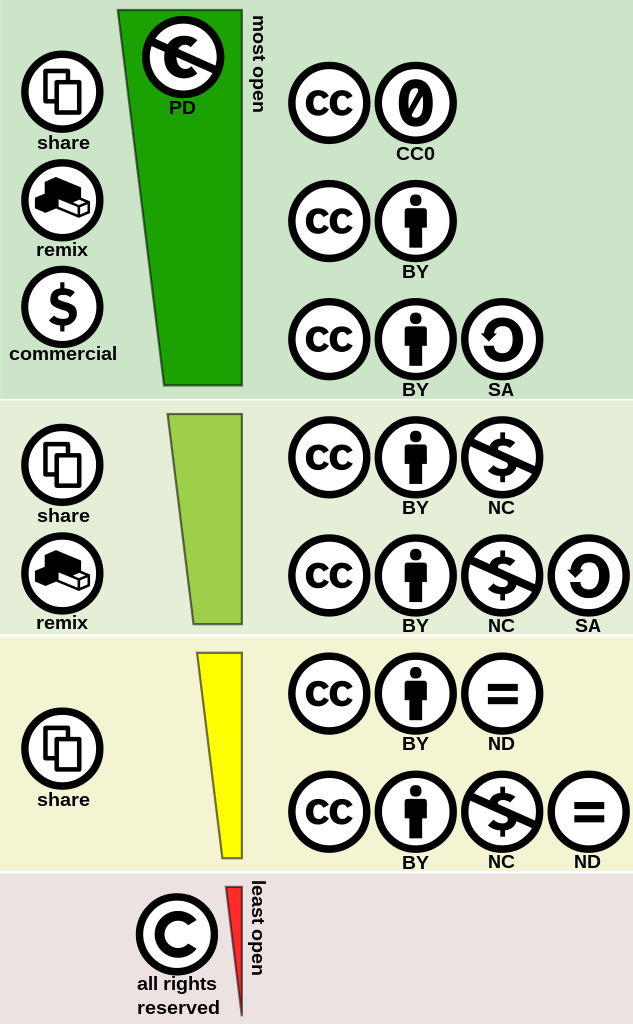
I metadati di cataloghi e dataset forniscono anche indicazioni sulle licenze di utilizzo e riutilizzo dei dati che descrivono. Nell’ambito delle licenze Copyleft la più famosa e utilizzata è la Creative Commons, che nelle sue ultime versioni comprende esplicitamente le banche dati.
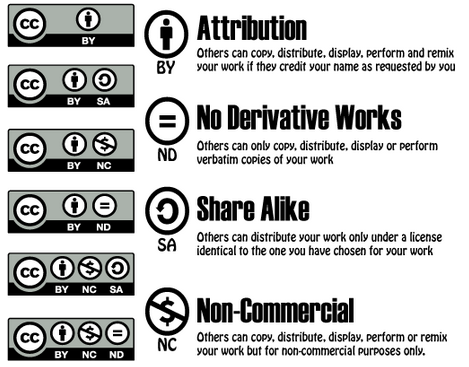
Per le banche dati esistono anche licenze dedicate, per esempio la ODbL (Open Data Commons Open Database License) promossa dalla Open Knowledge Foundation o la IODL (Italian Open Data License).
I dati aperti (o open data) sono dataset rilasciati con una licenza aperta.
Open means anyone can freely access, use, modify, and share for any purpose (subject, at most, to requirements that preserve provenance and openness).
Non tutte le licenze copyleft sono anche open, per esempio tra le Creative Commons solo CC0, CC-BY e CC-BY-SA. Lo sono anche ODbL e IODL.
Anche il codice sorgente è protetto dal diritto d’autore e il suo utilizzo e riutilizzo è normato dalla licenza che lo accompagna. Le licenze aperte (open source) ne permettono il riutilizzo per la costruzione di altri software (es. librerie condivise), specificando di volta in volta eventuali vincoli da rispettare.
Esistono molte licenze per il software, quelle più famose e utilizzate sono Apache, GPL, MIT. Per una panoramica completa c’è il sito tl;dr Legal.
Il codice sorgente di CKAN è rilasciato sotto la licenza AGPL-3.0 (GNU Affero General Public License v3), una licenza open source.
Attenzione alla licenza con cui sono rilasciati eventuali estensioni, devono essere compatibili con la AGPL di CKAN oppure bisogna soddisfare anche i loro vincoli aggiuntivi.
Comprehensive Knowledge Archive Network (CKAN)#
CKAN è mantenuto dalla Open Knowledge Foundation con la collaborazione di Datopian e Link Digital, oltre che di centinaia di contributori volontari.
Il codice sorgente è pubblicato su Github che ospita anche gli spazi di discussione e confronto della comunità di utilizzatori e sviluppatori. Al momento ha 3.600 star e 1.800 fork.
Su Stack Overflow le domande e risposte sono raccolte sotto un tag dedicato.
Esistono anche una mailing list ufficiale e una chat pubblica.
La documentazione ufficiale è gestita con Read the Docs, ma esiste anche un wiki pubblico su Github.
Le installazioni in Italia sono alcune decine, le più degne di nota sono il portale open data della Regione Toscana, quello della Regione Lazio, quello dell”INGV, quello del Comune di Lecce, ecc.
Storia del progetto#
Lo sviluppo di CKAN è iniziato nel maggio del 2006 come attestato dal changelog ufficiale, il primo commit pubblico è datato 18 gennaio a opera di Rufus Pollock.
La prima versione stabile è stata rilasciata l’11 maggio del 2010 e l’ultima disponibile (la 2.9.6), è uscita il 28 settembre scorso.
Al momento Datashades riporta più di 500 installazioni in tutto il mondo, per lo più in Europa (circa 200) e negli USA (circa 100). Gli utilizzatori principali sono per lo più istituzionali (enti governativi, istituti di ricerca), ma anche soggetti privati.
Stack tecnologico#
Il core di CKAN e tutte le sue estensioni sono scritte in Python per la parte di backend ed essendo un’applicazione web-based fa ampio uso di HTML, CSS e Javascript per la parte frontend.
Altre componenti rilevanti per il backend sono Jinja2 (v2) per il motore di template e Flask (v1) come web framework (da CKAN 2.4, prima era Pylons).
Per il frontend viene usato Bootstrap (v3) come css framework e jQuery come utility per Javascript.
Fino alla versione 2.8 (uscita nel maggio 2018 e tutt’ora supportata) il codice era compatibile solo con Python 2, il cui supporto è ufficialmente terminato il 31 dicembre 2019. La versione 2.9 (uscita nell’agosto del 2020) è la prima a essere compatibile con Python 3, anche se mantiene ancora la retrocompatibilità.
Le difficoltà incontrate in questo passaggio sono dovute principalmente al lavoro sulle estensioni (quasi 300), sia ufficiali che di terze parti, in molti casi poco mantenute.
Eseguire quindi CKAN in un ambiente Python 3 richiede una verifica attenta delle estensioni installabili, perché molte sono ormai non più compatibili.
La versione 2.10 attualmente in sviluppo dovrebbe togliere definitivamente il supporto a Python 2 e a tutte le vecchie estensiono non aggiornate opportunamente.
CKAN fa uso anche di componenti esterni dalla codebase: PostgreSQL come database principale, Solr come motore di ricerca e Redis come cache. Opzionale l’uso di Datapusher, un componente per la gestione avanzata delle risorse.
Temi, plugin e distribuzioni#
CKAN ha una struttura modulare e prevede l’integrazione di moduli aggiuntivi che ne possono estendere le funzionalità. Queste sono chiamate estensioni (CKAN Extensions, o ckanext).
Le estensioni sono di due tipi: plugin e temi. I primi permettono di modificare il comportamento interno di CKAN e di aggiungere funzionalità, i secondi permettono invece di personalizzare l’aspetto dell’interfaccia web.
In alcuni casi sono state costruite e messe a disposizione delle distribuzioni di CKAN con preinstallata una serie di estensioni pronte all’uso. È il caso del progetto CKAN-IT dell’ex Team per la Trasformazione Digitale basato su CKAN 2.6.8, ormai archiviato e deprecato.
Stato dell’arte e roadmap#
Al momento la versione stabile più recente è la 2.9.6, eseguibile in ambiente Python 3.
Le estensioni ufficiali più utilizzate sono abbastanza aggiornate, per quelle di terze parti c’è un’utile Awesome List.
L’estensione ckanext-dcatapit che aggiunge il supporto a DCAT-AP_IT è stata aggiornata e richiede ckanext-dcat e (opzionalmente) ckanext-spatial, entrambe ufficiali.
L’attuale roadmap non riporta una data prevista di rilascio della versione 2.10, ma l’aggiornamento delle estensioni è tracciato in una issue dedicata.
Alternative#
Oltre CKAN ci sono altri DMS open source disponibili, il più famoso dei quali è DKAN, una distribuzione di Drupal (v8) compatibile con lo schema dati e le API di CKAN.
Sempre ispirato a CKAN c’è anche JKAN, un DMS molto leggero basato sul generatore di siti statici Jekyll.
Sul mercato sono presenti numerose soluzioni enterprise, la più famosa forse è Socrata, alla base del portale open data della Regione Lombardia.
Laboratorio#
Attività proposte:
Esplorazione guidata del portale open data della Regione Toscana (dati.toscana.it) e del portale di INGV (data.ingv.it).
Censimento dei portali open data italiani basati su CKAN: forms.gle/QdZyi7GrQP5sisF47.